Nous vous avons dit en parlant des classes que ces dernières avaient presque entièrement disparu parce qu’elles étaient devenues obsolètes. Elles ont été remplacées par un système d’adressage plus fiable et plus performant, à savoir l’adressage CIDR, qui est l’objet de ce chapitre. Étant donné qu’il s’agit du système d’adressage utilisé actuellement, vous feriez mieux d’être plus concentrés que lorsque nous avons traité des classes.  C’est parti !
C’est parti !
- Révision de l'adressage par classes
- CIDR et le supernetting
- Les masques à longueurs variables (VLSM)
Révision de l'adressage par classes
Pour ne pas transformer cette section en cours d’histoire, nous vous proposons de lire cet article pour plus d’informations à caractère « culturel » sur la naissance et l’évolution d’Internet.
Nous allons revoir le fonctionnement de l’adressage par classes pour vous préparer à la suite du tutoriel.
Les cours sur les réseaux ne sont pas toujours à jour, aussi la majorité des étudiants continue à croire que les classes sont toujours d’actualité. Elles ont bien existé, mais elles ont été supplantées par l’adressage CIDR.
L’adressage par classes est un système utilisant une architecture réseau appelée en anglais classful network, c’est-à-dire « réseau dans les classes ». Cette expression traduit que le principe — majeur, sinon l’unique — de ce système d’adressage est de répartir les adresses IP par classes.
Le réseau ayant pour but de permettre la communication entre machines, les créateurs de la pile TCP/IP se sont inspirés du monde réel pour créer un système de communication informatique. Dans une société donnée, des individus vivent dans des maisons (en général), parlent une langue, ont un nom unique, vivent parfois dans des villes, occupent certaines fonctions, ont des responsabilités et des droits. Un système de communication informatique reprend plus ou moins ces grandes lignes : des individus (hôtes) parlent des langues (protocoles), ont des noms uniques (adresses IP), vivent dans des maisons (sous-réseau ou réseau, c’est selon), occupent des fonctions (clients, serveurs, passerelles, routeurs, etc.), ont des responsabilités (transmettre des données à la demande du client, distribuer automatiquement des adresses IP pour le cas d’un serveur DHCP) et des droits (réclamer un renouvellement d’adresse IP, demander l’identité d’un autre hôte, exiger un mot de passe, etc.).
Ainsi, pour rendre opérationnel ce tout nouveau système de communication, il y avait une espèce de sac plein de noms (adresses IP). Alors, on assignait un nom (une adresse IP) à chaque individu (hôte). Pour gérer cette distribution d’adresses, on a créé l’adressage par classes.
Pour reprendre un exemple, imaginez que vous ayez 10 000 prénoms à attribuer à autant de nouveau-nés. Pour mieux gérer cette attribution, vous pourriez classer les prénoms par ordre alphabétique : tous les prénoms commençant par un A sont réunis dans un dossier « Prénoms A », etc. Alors, si une dame venait vous demander dix prénoms pour ses dix futurs enfants, vous n’auriez qu’à lui demander les contraintes auxquelles doivent répondre ces prénoms :
« Je veux des prénoms qui commencent par la lettre A et constitués de cinq lettres », dirait-elle.
Rien de plus simple que de regarder votre dossier « Prénoms A » et d’en choisir dix. Mais que se passerait-il si, après avoir reçu les dix prénoms, la dame ne mettait au monde qu’un seul enfant (exemple très original  ) ? Quid des neuf autres prénoms ? Ce serait du gaspillage !
) ? Quid des neuf autres prénoms ? Ce serait du gaspillage !
Le système d’adressage par classes fonctionne selon le même principe : les adresses IP sont rangées par classes et dans chacune d’elles se trouvent des plages. Si une entreprise demandait des adresses pour cent ordinateurs, on choisirait la classe lui offrant ce nombre d’adresses et on lui offrirait des adresses IP issues de cette classe.
Le problème de ce système d’adressage est le pourcentage assez élevé de perte d’adresses. Nous avons vu que toutes les adresses IP de la classe A, par exemple, nous permettaient d’obtenir 16 777 214 adresses IP par réseau en utilisant les masques par défaut. Cela dit, l’entreprise qui voudrait une adresse IP pour un réseau de 10 000 hôtes aurait quand même 16 767 214 d’adresses en surplus. Quelle perte !
Si l’adressage par classes n’avait pas été remplacé depuis les années 1990, aujourd’hui nous utiliserions presque exclusivement les adresses IPv6, car nous aurions très vite connu une pénurie d’adresses. C’est pourquoi un nouveau système d’adressage, capable de réduire au minimum le gaspillage d’adresses IP et de faciliter considérablement le routage, a été mis en place. Nous allons le voir dans la prochaine section.
CIDR et le supernetting
La compréhension de cette section demande beaucoup de concentration. Vous êtes priés de rester attentifs tout au long de votre lecture. Prenez une feuille et un crayon pour faire les calculs au même moment que nous. Si vous vous contentez de les lire comme on lirait un roman, vous les trouverez très difficiles. Nous ne nous attendons pas non plus à ce que vous maîtrisiez le supernetting du premier coup : même des étudiants ont du mal à appréhender cette notion.
L’adressage sans classes (ou adressage CIDR) est le système de gestion et d’allocation d’adresses IP le plus utilisé aujourd’hui. Ce système, qui est régi par les RFC 1518 et 1519, a été conçu pour remplacer l’adressage par classes pour les raisons que nous avons évoquées dans les chapitres précédents. Le but de ce nouveau système s’articule autour de deux points :
- Économiser les adresses IP.
- Faciliter le routage.
CIDR ? Ce ne serait pas plutôt cidre ? 
Nous parlons de réseaux et non de boissons…  CIDR est l’acronyme de Classless Inter Domain Routing (« routage sans classes entre domaines »). Plutôt bizarre, non ? En bref, par CIDR comprenez « routage effectué entre domaines qui n’utilisent pas les classes ». On comprend alors que le réseau Internet est fondé sur ce système d’adressage. Logique, quand on y pense… Sinon, comment un système d’adressage par classes aurait-il pu supporter plus de 2 milliards d’internautes ? Depuis les années quatre-vingt-dix, nous n’aurions plus d’adresses IP disponibles.
CIDR est l’acronyme de Classless Inter Domain Routing (« routage sans classes entre domaines »). Plutôt bizarre, non ? En bref, par CIDR comprenez « routage effectué entre domaines qui n’utilisent pas les classes ». On comprend alors que le réseau Internet est fondé sur ce système d’adressage. Logique, quand on y pense… Sinon, comment un système d’adressage par classes aurait-il pu supporter plus de 2 milliards d’internautes ? Depuis les années quatre-vingt-dix, nous n’aurions plus d’adresses IP disponibles.
En anglais, les adresses IP utilisant l’adressage CIDR sont appelées classless addresses par opposition aux classful addresses, qui désignent celles qui utilisent l’adressage par classes. Habituez-vous à ce vocabulaire qui est très présent dans les documentations en anglais.
Quand nous parlons d’assignation d’adresses IP, en tant qu’administrateur d’un réseau, nous devons examiner deux choses :
- Les contraintes administratives pour obtenir et allouer les adresses.
- L’aspect technique (sous-entendu le routage, le plus souvent) que cela implique.
CIDR répond mieux aux contraintes techniques.
CIDR : le comment
Nous allons maintenant nous focaliser sur le comment, étant donné que vous savez déjà pourquoi ce nouveau système a été créé.
Soit l’adresse 192.168.10.0/23. À ce stade, vous êtes censés savoir que le nombre après le slash (/) équivaut au nombre de bits masqués. Si vous avez encore des difficultés, nous vous recommandons la relecture de la sous-partie sur la notation du masque.
Bien ! 192.168.10.0/23 applique un masque de 255.255.254.0 au réseau 192.168.10.0. Grâce à cette notation, nous pouvons calculer (et vous êtes censés savoir le faire seuls à présent) l’étendue du sous-réseau qui ira donc de 192.168.10.0 à 192.168.11.255 (si nous incluons l’adresse de diffusion ou broadcast address), dans un réseau sans classes. Par contre, si nous étions dans un réseau n’utilisant pas l’adressage CIDR, 192.168.10.0/23 représenterait une fusion de deux sous-réseaux de la classe C, 192.168.10.0 et 192.168.11.0 ayant chacun un masque de sous-réseau de… 255.255.255.0.
Cela dit, avec l’adressage CIDR, le masque /23 nous donne l’équation suivante :
192.168.10.0/23 (adressage CIDR) = 192.168.10.0/24 (ou 255.255.255.0) + 192.168.11.0/24 (ou 255.255.255.0)
Vous voyez ? Nous avons la possibilité d’utiliser un seul réseau qui fusionne plusieurs sous-réseaux. Cette fusion de sous-réseaux, dite aussi supernetting, est l’essence même de CIDR. Cette technique est également appelée résumé de routes (route summarization en anglais).
Cette pratique viole la règle d’or du subnetting. Vous vous en souvenez ? Celle des 0 (network ID) et des 1 (broadcast address). Tous les routeurs qui supportent ce type d’adressage ignorent également cette règle.
Pour implémenter un réseau fondé sur l’adressage CIDR, il faut utiliser un protocole qui puisse le supporter. Il en existe plusieurs, tels que BGP et OSPF. Si le protocole ne supporte pas ce type d’adressage, le routage échouera dans ce réseau. En général, les petits LAN et les réseaux « maison » n’implémentent pas l’adressage CIDR.
Comment résumer une route
Dans l’adressage par classes, nous utilisions le subnetting pour réduire la congestion d’un réseau en le subdivisant en plusieurs sous-réseaux. Toujours est-il que nous perdions quelques adresses IP, étant donné que plusieurs sous-réseaux utilisaient un même masque. Cela dit, chaque sous-réseau avait le même nombre d’adresses. « Supernetter » un réseau est exactement le contraire de « subnetter » un réseau, sauf qu’ici, il ne s’agit plus de l’adressage par classes mais de l’adressage CIDR. Tous ces sous-réseaux peuvent donc être fusionnés et rassemblés sous un seul préfixe.
Un exemple vaut mieux que tout ce pavé.
Si nous avons quatre subnets tels que :
- Subnet 1 : 192.168.0.0/24 soit 11000000. 10101000. 00000000.00000000/24
- Subnet 2 : 192.168.1.0/24 soit 11000000. 10101000. 00000001.00000000/24
- Subnet 3 : 192.168.2.0/24 soit 11000000. 10101000. 00000010.00000000/24
- Subnet 4 : 192.168.3.0/24 soit 11000000. 10101000. 00000011.00000000/24
Nous remarquons que ces quatre subnets ont bien le même préfixe /24 : nous pouvons les fusionner sous un seul préfixe. Par conséquent, nous obtenons la route suivante : 192.168.0.0/22 soit 11000000.10101000.00000000.00000000/22.
Comment avez-vous obtenu le /22 alors que nous avions /24 au départ ?
Très belle question ! Nous avons simplement appliqué la technique d’agrégation de routes. Supernetter, c’est la même chose qu’agréger des routes. Le résultat obtenu est donc appelé route agrégée ou route résumée. Pour obtenir le /22, nous avons suivi quatre étapes bien précises que vous devez suivre également.
Étape 1 : détecter les réseaux ayant le même préfixe
Dans cette étape, nous avons pris quatre réseaux ayant le même préfixe (/24) : il s’agit de 192.168.0.0, 192.168.1.0, 192.168.2.0 et 192.168.3.0.
Étape 2 : convertir des réseaux en binaire
Ensuite, nous avons converti chaque adresse réseau en binaire. Pourquoi ? Parce que c’est important pour l’étape 3.
Étapes 3 et 4 : détecter les motifs entre les sous-réseaux en binaire (étape 3) et les compter (étape 4)
Ne paniquez pas : ce n’est pas difficile. Quand nous avons converti les quatre sous-réseaux en binaire, qu’avons-nous obtenu ?
- Subnet 1 : 11000000. 10101000. 00000000. 00000000
- Subnet 2 : 11000000. 10101000. 00000001. 00000000
- Subnet 3 : 11000000. 10101000. 00000010. 00000000
- Subnet 4 : 11000000. 10101000. 00000011. 00000000
Y a-t-il quelque chose de commun à ces quatre sous-réseaux ? Rien ? Vous en êtes sûrs ? Nous allons vous faciliter la tâche.
- Subnet 1 : 11000000.10101000.00000000.00000000
- Subnet 2 : 11000000.10101000.00000001.00000000
- Subnet 3 : 11000000.10101000.00000010.00000000
- Subnet 4 : 11000000.10101000.00000011.00000000
Et maintenant ? 
Tous ces sous-réseaux ont 11000000.10101000.000000 en commun. Comptons le nombre de bits : il y en a 22, n’est-ce pas ? 22 sera donc notre nouveau préfixe. Le network ID sera la plus petite adresse IP parmi les quatre, soit 192.168.0.0. Enfin, la nouvelle route, la route résumée ou agrégée, sera 192.168.0.0 /22.
Voilà, vous savez tout sur le supernetting et le subnetting. Nous y reviendrons certainement une fois que vous maîtriserez le routage, afin que nous constations combien il est efficace de résumer les routes pour ne pas alourdir la table de routage.
Quelques exercices pour la route
Ne croyez pas que nous allons vous laisser filer comme ça, il vous faut pratiquer et encore pratiquer !
Exercice 1 : supernetting
Votre premier exercice est relativement simple. Plus haut, nous avons pris le cas d’un réseau 192.168.10.0/23 et nous avons évoqué l’équation suivante :
192.168.10.0/23 (adressage CIDR) = 192.168.10.0/24 (ou 255.255.255.0) + 192.168.11.0/24 (ou 255.255.255.0)
Prouvez que 192.168.10.0/23 est bel et bien une fusion (une route agrégée) de 192.168.10.0/24 et 192.168.11.0/24. C’est très simple, il suffit de respecter les étapes que nous avons définies plus haut.
Exercice 2 : stagiaire chez Link it Technology
Vous êtes stagiaire dans une entreprise éditrice de logiciels nommée Link it Technology. Le réseau de ladite entreprise est constitué de 192 hôtes parmi lesquels 4 serveurs :
-
Srvprog est le serveur que les programmeurs (au nombre de 47) de l’entreprise utilisent. Il héberge un nombre important d’applications.
-
Srvcomp est le serveur des 76 comptables. Il héberge également un nombre important d’applications de comptabilité.
-
Srvprint est le serveur d’impression des secrétaires. On en compte 33 qui effectuent un nombre considérable d’impressions par jour, ce qui alourdit le réseau et empêche aux autres services de communiquer plus rapidement avec leurs serveurs respectifs.
-
Srvboss_backup est le serveur sur lequel sont sauvegardés tous les fichiers des chefs de division. Le système de backup de l’entreprise est automatique : chaque fois qu’un fichier est modifié et sauvegardé, une copie est sauvegardée aussitôt sur ce serveur. Les chefs de division, tasse de café à la main chaque matin, modifient plusieurs fichiers. Ils sont au nombre de 36 (les chefs, pas les fichiers !).
Votre chef se plaint de la congestion du réseau et vous demande de mettre en place un plan d’adressage pour minimiser le trafic. Vous devrez donc, à partir de l’adresse réseau 120.12.0.0/18, aboutir à une solution satisfaisante. Dans ce cas précis, il vous est demandé de subnetter ce réseau en quatre :
- Un réseau netprog pour tous les développeurs de l’entreprise et leur serveur.
- Un réseau netcomp pour tous les comptables et leur serveur.
- Un réseau netsecr pour tous les secrétaires et leur serveur de fichiers.
- Un réseau netbackup pour tous les chefs de division et leur serveur backup.
Pour cet exercice, nous supposerons que les sous-réseaux ne communiquent pas entre eux, donc que le trafic reste interne. Par conséquent, nous n’avons pas besoin de routeurs et de calculer les plages pour leurs interfaces. Dans la réalité, ce calcul est obligatoire mais ignorez cette étape pour cet exercice. Vous le ferez dans la prochaine sous-partie.
À partir de l’énoncé ci-dessus, votre mission est triple :
- Déterminer le network ID de chaque subnet et leur masque.
- Déterminer les plages d’adresses de chaque subnet en incluant leur broadcast address.
- Appliquer la technique du supernetting pour avoir une route résumée des subnets que vous aurez obtenus.
Les sous-réseaux n’ont pas le même nombre d’hôtes ; ainsi pour déterminer combien de bits il faut masquer, vous devrez vous focaliser sur le plus grand sous-réseau. Dans notre scénario, il s’agit du sous-réseau netcomp (76 hôtes pour les comptables). Trouvez un masque qui vous permette d’avoir au moins 76 hôtes par sous-réseau. Nous perdrons des adresses, certes, mais vous ne savez pas encore comment implémenter des masques à longueur variable. Pour cela, rendez-vous à la prochaine sous-partie.
Voici trois possibilités de résoudre l’exercice 2.
Cas 1. On veut juste déterminer les sous-réseaux et plages associées pour le nombre d’hôtes et de serveurs donnés. Dans ce cas, on commence par trier les sous-réseaux par nombre d’adresses souhaitées : netcomp (76 clients + 1 serveur), netprog (47 clients + 1 serveur), netbackup (36 clients + 1 serveur), netsecr (33 + 1).
On commence donc par netcomp. Il va nous falloir un sous-réseau avec 77 adresses minimum. On cherche la puissance de deux supérieure. 26 = 64, 27 = 128, on va prendre 128 bits. Pour netcomp, on réserve donc 7 bits pour le host id, ce qui nous fait un masque en /25, soit 11111111.11111111.11111111.10000000. Le network id sera le premier disponible, à savoir 120.12.0.0. L’adresse du premier hôte sera 120.12.0.1 et le dernier 120.12.0.126 (on gardera 120.12.0.127 pour le broadcast).
Pour netprog, il nous faut 48 adresses. Si on repart de la fin du sous-réseau précédent, on peut refaire un sous-réseau en exploitant les adresses en 120.12.0.xxx inutilisées (de 128 à 255). On ne pourra toutefois pas aller plus loin : il est mathématiquement impossible de trouver une adresse de réseau et un masque qui permettraient de couvrir les adresses de 120.12.0.128 à 120.10.1.255 (par exemple) sans englober aussi le premier sous-réseau. Procédons comme pour netcomp en trouvant une puissance de 2 supérieure à 48. 25 = 32, 26 = 64. On va donc prendre 6 bits, ce qui nous fait un masque en /26 et une plage allant de 120.12.0.128 à 120.12.0.191. La première adresse d’hôte est 120.12.0.129, la dernière 120.12.0.190, le broadcast 120.12.0.191.
On peut faire exactement pareil pour netbackup, on trouvera 120.12.0.193 pour le premier hôte, 120.12.0.254 pour le dernier, 120.12.0.255 pour le broadcast.
Enfin, pour le dernier, on fait la même chose : on part de l’adresse suivante disponible (120.12.1.0), on prend 6 bits et on a une plage 120.12.1.0 - 120.12.1.63.
On a optimisé au maximum les adresses à notre disposition, ce qui nous en laisse plein pour d’autres usages. Cette méthode a un inconvénient : elle limite l’extension des sous-réseaux. Si on veut rajouter 20 hôtes à netprog, ça en fera 68 et tout notre plan sera fichu ! Mais on peut aussi procéder d’une autre manière, en considérant qu’on n’aura jamais besoin de créer d’autres sous-réseaux et qu’on veut juste de la place pour ces quatre sous-réseaux là.
Cas 2. Dans ce cas, on peut couper le réseau en quatre parts égales. Nos adresses vont de 120.12.0.0 à 120.12.63.255. On peut ainsi définir arbitrairement les plages suivantes : 120.12.0.0 - 120.12.15.255, 120.12.16.0 - 120.12.31.255, 120.12.32.0 - 120.12.47.255, 120.12.48.0 - 120.12.63.255. C’est beaucoup plus facile mais moins souple : en cas de création de nouveaux sous-réseaux, il faudra tout revoir.
Cas 3. Heureusement, une méthode de super fainéant existe ! Elle combine les avantages des deux autres méthodes, à savoir la flexibilité pour ajouter des sous-réseaux et pour ajouter des hôtes. Il suffit de se dire qu’on va mettre 256 adresses pour tout le monde ! Pourquoi 256 ? Parce que c’est suffisant pour tous et ça laisse de la marge de manœuvre. Et surtout, c’est hyper facile à calculer : du /24 pour tous, et on a netcomp : 120.12.0.0–255, netprog : 120.12.1.0–255, netbackup : 120.12.2.0–255, netsecr : 120.12.3.0–255. Et voilà, une demi-heure de gagnée, ça fait une pause café bien méritée !
Les masques à longueurs variables (VLSM)
Comme précédemment, la compréhension de cette section demande beaucoup de concentration. Papier et crayon vous seront utiles pour faire des calculs et prendre des notes. Si vous vous contentez de lire, vous risquez de ne pas retenir grand-chose !
VLSM, pour Variable Length Subnet Mask (soit masque de sous-réseaux à longueur variable) est une technique utilisée dans le but de mieux gérer les adresses IP, tout comme le CIDR. En fait, VLSM est une extension de CIDR. La différence est que le CIDR est plus utilisé au niveau internet et le VLSM est plus utilisé dans un réseau local, mais les deux permettent de minimiser la perte d’adresses.
Pour mettre en place un réseau aux masques à longueurs variables, il faut être sûr que les routeurs supportent les protocoles compatibles au VLSM. Quelques-uns de ces protocoles sont OSPF, EIGRP, RIPv2, IS-IS. Vous n’avez pas besoin de connaître ce qu’ils sont et ce qu’ils font, nous étudierons quelques-uns d’entre eux en temps voulu.
Son utilité ?
Pour comprendre à quoi sert l’implémentation des masques de sous-réseaux variables, nous allons considérer un scénario.
Vous avez un réseau de 250 hôtes. Vous voulez réduire la congestion de ce dernier et décidez de le subnetter en plusieurs sous-réseaux. Grâce aux techniques du subnetting et aux règles que vous avez apprises, vous décidez de le subnetter en cinq réseaux de 50 hôtes chacun.
Il est impossible d’obtenir cinq réseaux de 50 hôtes pile chacun (d’ailleurs, c’est une mauvaise pratique de choisir un masque qui nous donne exactement le nombre d’hôtes dont nous avons besoin). À la rigueur, nous pourrons obtenir cinq réseaux pouvant contenir au moins 50 hôtes. Dans ce cas, le réseau pourrait contenir un maximum de 62 hôtes si on masque 2 bits.
Vous obtenez alors vos cinq sous-réseaux et vous êtes contents : le but est atteint. 
Maintenant, imaginez que vous êtes un administrateur réseau employé dans une entreprise. Vous avez un sous-réseau 192.168.100.0/24. Votre patron vous dit qu’il souhaite une segmentation par fonctions, comme nous l’avons étudié dans l’analyse des contraintes et plan d’adressage. Il vous donne les spécifications suivantes :
- Un sous-réseau de 50 hôtes, uniquement pour les secrétaires de l’entreprise.
- Deux sous-réseaux de 12 hôtes chacun, pour les techniciens et les comptables.
- Un sous-réseau de 27 hôtes pour les développeurs d’applications.
Pour une meilleure compréhension de ce qui nous est demandé, considérons le schéma ci-dessous auquel vous devez vous référer.

Les cercles rouges représentent les sous-réseaux que nous voulons obtenir. Nous avons au total cinq routeurs :
- routeur_AE, qui relie le réseau A et E ;
- routeur_link, qui relie les réseaux F, G et H au réseau E ;
- etc.
N.B. : les réseaux E, F, G et H sont en orange pour une raison précise. Il s’agit en fait des interfaces de liaison.
Comment allez-vous mettre cela en place en subnettant ? Ce n’est pas possible, car le subnetting nous permet d’avoir plusieurs sous-réseaux ayant un même nombre d’hôtes et un même masque, mais ayant des portées d’adresses différentes pour marquer la fin et le début d’un sous-réseau. Or dans notre étude de cas, le patron (le boss, quoi  ) nous demande de créer des sous-réseaux aux masques à longueurs variables. En fait, si on analyse bien la situation, il nous faut créer des sous-réseaux différents dans des sous-réseaux, c’est ce qu’on appelle subnetter un subnet (sous-réseauter un sous-réseau ). Il faudra donc, à partir d’un network ID, obtenir un masque différent pour chaque sous-réseau.
Si nous en étions encore à l’adressage par classes, cela serait impossible car il faut un même masque pour chaque sous-réseau. Ainsi, un réseau tel que 192.168.187.0 n’aurait qu’un seul masque, soit 255.255.255.0.
) nous demande de créer des sous-réseaux aux masques à longueurs variables. En fait, si on analyse bien la situation, il nous faut créer des sous-réseaux différents dans des sous-réseaux, c’est ce qu’on appelle subnetter un subnet (sous-réseauter un sous-réseau ). Il faudra donc, à partir d’un network ID, obtenir un masque différent pour chaque sous-réseau.
Si nous en étions encore à l’adressage par classes, cela serait impossible car il faut un même masque pour chaque sous-réseau. Ainsi, un réseau tel que 192.168.187.0 n’aurait qu’un seul masque, soit 255.255.255.0.
TD : implémentation des masques à longueurs variables
Pour comprendre le calcul des masques variables, nous allons implémenter cela dans un réseau local. La solution au scénario ci-dessus se fera comme dans un TD. Les prérequis pour pouvoir suivre et comprendre ce TD sont :
- Maîtrise de la notion de masque de sous-réseau et son utilité.
- Maîtrise des 8 premières puissances de 2.
- Maîtrise de la conversion du binaire au décimal et l’inverse.
- Maîtrise de la notion du subnetting et sa procédure.
- Maîtrise de la notion de passerelle et son rôle.
- Maîtrise de l’adressage CIDR et sa notation.
Pour réussir ce challenge posé par votre patron, il vous faudra suivre des étapes de planification d’adresses. C’est parti ! 
Étape 1 : se focaliser sur le sous-réseau qui a le plus grand nombre d’hôtes
Nous allons commencer par localiser le sous-réseau qui a le plus grand nombre d’hôtes, le sous-réseau A en l’occurrence (50 hôtes).
Combien de bits devons-nous utiliser pour avoir au moins 50 hôtes ?
On y va avec les puissances de deux et notre formule 2^n-2.
- 2^1–2 = 0 ;
- 2^2–2 = 2 ;
- ………………………
- 2^6–2 = 62. Stop ! Nous allons donc devoir garder 6 bits de la partie « host » de notre masque.
En binaire, nous obtenons donc : 11000000 . 10101000 . 01100100. nnhhhhhh avec n les bits disponibles pour le réseau, et h les bits qu’on ne doit pas masquer pour obtenir au moins 50 hôtes.
Étape 2 : choisir un network ID pour l’étape 1
Une fois que nous avons résolu le plus grand sous-réseau, il nous faut choisir quel subnet ID donner à ce sous-réseau. Nous avons retenu, dans l’étape 1, que nous n’avions que 2 bits pour le sous-réseau, ce qui donne (en se focalisant sur le 4e octet) les combinaisons suivantes que vous êtes censé trouver les doigts dans le nez :
- 00hhhhhh ;
- 01hhhhhh ;
- 10hhhhhh ;
- 11hhhhhh.
En remplaçant le h (pour hôte) par 0 (puisque nous ne les masquons pas), on obtient le network ID pour chaque sous-réseau, soit les suivants :
- 00000000 = .0
- 01000000 = .64
- 10000000 = .128
- 11000000 = .192
N’ayant que 2 bits masqués pour le sous-réseau, on peut donc utiliser un masque de /26 ou 255.255.255.192 pour chacun de ses sous-réseaux obtenus, juste comme on ferait dans un réseau utilisant l’adressage par classe.
Voilà. Nous avons 4 network ID, vous pouvez choisir n’importe lequel pour le sous-réseau A. Dans ce TD, nous choisissons au hasard .64, soit la notation 192.168.100.64/26 (network ID/masque). Les autres sous-réseaux devront se contenter des trois sous-réseaux restants.
D’où vient le /26 ?
C’est une blague ? Vous êtes censés savoir comment on a obtenu le /26. Nous avons gardé 6 bits pour les hôtes, or une adresse IP est constituée de 32 bits, donc 32–6 = 26 bits.
Étape 3 : se focaliser sur le second plus grand sous-réseau
Le second plus grand sous-réseau contient dans notre exemple 27 hôtes pour les développeurs d’applications. Il s’agit du sous-réseau B. Nous allons refaire les calculs de l’étape 1. Nous n’allons donc pas détailler cela. Nous aurons besoin d’au moins 5 bits pour les hôtes (2^5–2 = 30, 30>27, donc O.K.). En binaire, nous avons :
11000000 . 10101000 . 11001000 . nnnhhhhh
N’est-ce pas ? Alors, nous pouvons faire toutes les combinaisons possibles avec les trois bits pour n, n’est-ce pas ? Faux !
Faux ?  Nous n’avons besoin que de 5 bits. C’est logique puisque nous en avons trois consacrés au sous-réseau, non ?
Nous n’avons besoin que de 5 bits. C’est logique puisque nous en avons trois consacrés au sous-réseau, non ?
Oui, mais non ! Si vous le faites ainsi, vous êtes en train de subnetter le network ID originel soit le 192.168.100.0, alors que c’est ce que nous avons déjà fait dans l’étape 1, en masquant 2 bits pour le réseau. Mais ici, nous voulons subnetter un subnet. C’est totalement différent, nous allons donc prendre un sous-réseau déjà obtenu dans l’étape 1 et le re-subnetter à nouveau. Avouez que cela devient complexe.
Dans l’étape 1, nous avions obtenu 4 combinaisons, soit 4 network ID. Nous avons sélectionné le 255.255.255.192 soit le /26 pour le sous-réseau A. Il nous reste donc trois network ID disponibles, soit :
- 00000000 = .0/26
- 01000000 = .64/26 // sous-réseau A
- 10000000 = .128/26
- 11000000 = .192/26
Choisissons le .128 dont le network ID sera 192.168.100.128/26, ce qui donne en binaire (focus sur le 4e octet) : 10000000. Or nous n’avons besoin que de 5 bits disponibles pour les hôtes, alors qu’ici nous en avons 6. Nous allons donc supprimer un bit pour les hôtes et l’allouer au sous-réseau.
10n00000.
Voilà ! Nous avons donc 3 bits pour le sous-réseau et 5 pour les hôtes. Maintenant, nous pouvons donc créer deux sous-réseaux à partir du sous-réseau original. C’est cela l’intérêt du VLSM, on subdivise encore un sous-réseau. Nous avons donc :
- 10000000 = .128
- 10100000 = .160
Bravo, vous venez de subnetter un subnet comme un pro, vous devez en être fier.
En résumé, voici ce que nous avons fait :
-
Nous disposions à l’origine d’un network ID de 192.168.100.0/24.
-
Nous l’avons subdivisé pour obtenir un sous-réseau ayant un masque de 192.168.100.64/26 et pouvant contenir au moins 50 hôtes.
-
Nous avons pris le sous-réseau obtenu dans l’étape 2 et l’avons re-subnetté en deux sous-réseaux (.128 et .160) qui auront un masque de… /27.
Comment avez-vous obtenu le /27 ?
Encore la même question ? Dans les deux sous-réseaux que nous avons obtenus, nous avions 3 bits pour les sous-réseaux et 5 pour les hôtes. Nous avons donc laissé 5 bits non masqués pour obtenir au moins 27 hôtes (2^5–2 = 30). Une adresse IP valant 32 bits, 32 – 5 = 27. D’où les réseaux .128 et .160 qui ont tous deux un même préfixe : /27.
Ici également, nous pouvons choisir n’importe quel network ID : choisissons le premier, soit .128/27. Le sous-réseau restant (.160/27) pourrait être utilisé dans le futur, s’il y a agrandissement du sous-réseau.
Voici la liste des network ID que nous avons obtenus depuis l’étape 1 :
- 00000000 = .0/26 | libre pour être re-subnetté
- 01000000 = .64/26 | sous-réseau A
- 10000000 = .128/26 | Nous ne pouvons plus l’utiliser, il a été re-subnetté
- 10000000 = .128/27 | Nous prenons celui-ci pour le sous-réseau B
- 10100000 = .160/27 | nous gardons celui-ci pour le futur
Mais… mais… comment obtient-on 128/26 ET 128/27 ?
C’est faire preuve de concentration que de poser cette question ! La réponse est simple : nous avions 128/26 au départ, mais comme nous l’avons re-subnetté, nous avons changé de masque, en gardant le network ID originel : nous avons donc le 2e 128, mais avec un masque de /27.
Étape 4 : se focaliser sur le troisième plus vaste sous-réseau
Le troisième plus vaste sous-réseau est le réseau C et D de 12 hôtes chacun. Cette étape est exactement la répétition des étapes 1 et 3, avec les mêmes calculs. Nous avons besoin d’au moins 12 hôtes. 2^4–2 = 14, ce qui nous suffit. Nous allons donc garder 4 bits pour les hôtes et disposerons donc de 4 bits pour la partie réseau du masque. Au lieu de reprendre le network ID de base et masquer 4 bits comme nous l’aurions fait dans un cas de subnetting classique, nous allons devoir re-subnetter un subnet déjà subnetté comme nous l’avons fait dans l’étape 3. Vous avez le choix : vous pouvez décider de re-subnetter le 192.168.100.0/26, 192.168.100.128/27 ou 192.168.100.160/27. Pour ce TD, choisissez 192.168.100.160/27. Nous avons donc ceci en binaire :
10100000
Nous avons 5 bits libres pour les hôtes, ce qui était suffisant pour le réseau B qui nécessitait 27 hôtes. Mais pour le réseau C ou D, nous aurons une perte de 27–12 = 15 hôtes, et c’est ce que nous voulons éviter. Nous allons donc retirer un bit de la partie hôte et l’allouer à la partie réseau de notre masque de manière à avoir 4 bits pour les hôtes et 4 pour la partie réseau car 2^4–2 = 14, ce qui nous convient. Nous avons donc :
101**n**0000
- 10 représente ici les deux bits consacrés au réseau au départ dans l’étape 1. C’est notre motif de base : nous ne devons pas le changer, le reste de nos subnets en binaire doit commencer par 00.
- 1 représente le bit sur lequel nous nous sommes concentrés dans l’étape 3.
- n est le bit supplémentaire que nous allons ajouter à la partie réseau du masque de manière à ne rester qu’avec 4 bits pour les hôtes.
Grace à ce bit de plus que nous avons, nous pouvons donc avoir deux combinaisons (soit le laisser à 0 ou le masquer à 1), ce qui nous donne la possibilité d’obtenir deux autres sous-réseaux à partir du sous-réseau de base, ce qui nous donne (avec le focus sur le 4e octet toujours) :
- 10100000 = .160
- 10110000 = .176
Il ne nous reste plus qu’à trouver le nouveau masque pour ces deux nouveaux sous-réseaux, ce qui est simple puisque nous n’avons qu’à compter le nombre de bits masqués. Soit 11111111.11111111.11111111.11110000, puisque nous n’avons que 4 bits pour les hôtes, le reste des bits est donc masqué pour la partie réseau. Nous aurons donc un masque de 255.255.255.240 ou /28 pour la notation CIDR.
Résumons donc tous les subnets obtenus depuis l’étape 1 afin de choisir un network ID pour les réseaux C et D.
- 00000000 = .0/26 | subnet libre pour être re-subnetté
- 01000000 = .64/26 | déjà utilisé par le sous-réseau A
- 10000000 = .128/26 | Nous ne pouvons plus utiliser celui-ci, car nous l’avons re-subnetté
- 11000000 = .192/26 | subnet pour un futur agrandissement
- 10000000 = .128/27 | déjà utilisé pour le sous-réseau B
- 10100000 = .160/27 | nous ne pouvons plus l’utiliser, car nous l’avons re-subnetté
- 10100000 = .160/28 | Prenons celui-ci pour le sous-réseau C
- 10110000 = .176/28 | Prenons celui-ci pour le sous-réseau D
- Remarque 1 : nous nous retrouvons avec deux 160 : un avec /27 et l’autre avec /28, pour les mêmes raisons que nous avions deux 128. Nous vous avons expliqué cela.
- Remarque 2 : nous ne pouvons plus utiliser un sous-réseau déjà subnetté.
Cinquième et dernière étape : déterminer les network ID pour les interfaces de liaison
Regardez sur votre schéma. Comment allons-nous nouer ces sous-réseaux entre eux ? Par un routeur bien entendu, et c’est exactement ce que fait le routeur routeur_link dans le schéma. Mais comme chaque routeur, il possède deux interfaces de liaison. Il faut donc deux adresses IP pour relier F et E, deux pour relier G et E, et deux pour relier H et E. Nous pouvons le faire les yeux fermés en binaire, nous n’avons besoin de 2 bits car 2^2–2 = 2. Ça tombe pile-poil. Nous devons donc choisir un sous-réseau libre pour être re-subnetté. Vous pouvez choisir celui que vous voulez parmi les sous-réseaux libres que nous avons obtenu jusqu’ici. Pour suivre ce TD, choisissez le sous-réseau 00000000/26.
Ici également, nous nous rendons compte que ce sous-réseau a été subnetté de manière à obtenir au moins 50 hôtes (sous-réseau A), voilà pourquoi 6 bits sont disponibles pour les hôtes. Or nous n’avons besoin que de deux bits. Qu’allons-nous faire ? Exactement ce que nous avons fait dans les étapes précédentes, nous allons allouer 4 bits de plus à la partie réseau du masque pour ne rester qu’avec deux bits pour les hôtes. Nous obtenons donc ceci :
00**nnnn**hh
Maintenant nous avons 4 bits alloués au réseau, ce qui donne la possibilité d’obtenir 16 sous-réseaux (2^4) à partir de ce sous-réseau. Vous devez être capable de déterminer chacun de ces 16 sous-réseaux, mais comme nous sommes gentils aujourd’hui, nous vous écrivons les huit premiers, l’avant-dernier et le dernier. Nous avons donc :
- 00000000 = .0/30
- 00000100 = .4/30
- 00001000 = .8/30
- 00001100 = .12/30
- 00010000 = .16/30
- 00010100 = .20/30
- 00011000 = .24/30
- 00011100 = .28/30
- 00100000 = .32/30
- …………………………………………
- …………………………………………
- 00111000 = .56/30
- 00111100 = .60/30
N.B. : chacun de ces sous-réseaux nous donnera deux hôtes disponibles, vous pouvez donc choisir quatre sous-réseaux parmi les 16 pour les interfaces de liaison, c’est-à-dire pour les adresses IP de chaque interface du routeur. Nous allons choisir les quatre premiers, soit de .0/30 -.12/30.
Tenez, si on vous demandait d’agréger les 12 sous-réseaux restants (soit à partir de .16/30) en utilisant la technique du supernetting pour obtenir une seule route, laquelle obtiendrez-vous ?
Un indice ?
Suivez les étapes expliquées dans la sous-partie précédente.
Ne regardez la réponse qu’après avoir vraiment essayé de trouver : cela ne vous aide pas si vous ne faites pas un effort de pratiquer.
00010000 = .16/26 ou 255.255.255.192
Résumons chacun des sous-réseaux trouvés depuis l’étape 1 :
- 00000000 = .0/26 | nous ne pouvons plus utiliser celui-ci, nous l’avons re-subnetté
- 00000000 = .0/30 | utilisons celui-ci pour le sous-réseau E
- 00000100 = .4/30 | sous-réseau F
- 00001000 = .8/30 | sous-réseau G
- 00001100 = .12/30 | sous-réseau H
- 01000000 = .64/26 | sous-réseau A
- 10000000 = .128/26 | Nous ne pouvons plus utiliser celui-ci, car nous l’avons re-subnetté
- 11000000 = .192/26 | subnet pour un futur agrandissement
- 10000000 = .128/27 | sous-réseau B
- 10100000 = .160/27 | nous ne pouvons plus l’utiliser, car nous l’avons re-subnetté
- 10100000 = .160/28 | sous-réseau C
- 10110000 = .176/28 | sous-réseau D
Conclusion et exercices
Ce TD vous a certainement aidé à mieux assimiler le principe du VLSM et du Supernetting. Nous avons au passage revu un certain nombre de notions. En effet, nous avons pratiqué les calculs des puissances de 2, la conversion des masques du décimal au binaire et vice versa, le subnetting d’un réseau, l’interconnexion de deux sous-réseaux différents par le biais d’un routeur etc. Plusieurs autres cas de pratique viendront avec le temps pour vous faire pratiquer tout ce que nous avons appris depuis la première partie du cours : le design de l’infrastructure d’un réseau, l’analyse des contraintes et la mise en place de la meilleure infrastructure répondant au mieux aux besoins, la segmentation des réseaux selon des exigences, la planification d’un plan d’adressage, le diagnostic et bien d’autres joyeusetés qui vous donneront indubitablement un savoir-faire dans le domaine, savoir-faire assez solide pour être admis en stage d’entreprise dans le domaine du réseau.
Pour terminer, nous vous donnons quelques exercices, pas difficiles du tout.
Dans ce TD, nous n’avons fait que trouver les network ID de chaque subnet qui répondaient aux consignes de notre patron, ce qui, mine de rien, représente plus de 50 % du travail. À présent, votre travail consistera à la détermination des plages d’adresses pour chaque sous-réseau. Voici, en résumé, ce que vous devez faire :
- Pour chaque sous-réseau (A, B, C, D, E, F et G), déterminez les plages d’adresses. Dans ces plages, déterminez celles que vous allez assigner aux hôtes. Par exemple pour le réseau C, nous aurons 14 adresses utilisables, mais seulement 12 assignables car notre réseau ne comprend que 12 hôtes ; les deux autres seront une perte, certes, mais réduite au maximum.
- Choisissez la première adresse IP de chaque plage pour le routeur.
- Éditez le schéma que vous avez utilisé pour ce TD et inscrivez les adresses IP de chacune des interfaces de chaque routeur ainsi que leurs masques respectifs (notation avec un / exigée), pour obtenir quelque chose de similaire au schéma Figure 1.0 (les adresses IP sont fictives et nous avons omis les masques). Si vous ne pouvez pas l’éditer, contentez-vous de résumer cela dans un tableau.
- Ajoutez trois hôtes dans les réseaux A, B, C et D et inscrivez, à côté de chacun d’eux, leurs adresses IP et masques respectifs. Votre schéma doit ressembler au schéma Figure 1.1. (Ici également, les adresses IP sont fictives et nous nous limitons à un hôte par réseau pour gagner le temps. )
- Finalement, faites communiquer les hôtes de chaque réseau entre eux. C’est-à-dire, un hôte A1 du réseau A doit communiquer avec un hôte du réseau B, un autre du réseau C et un autre du réseau D. Vous n’avez pas besoin d’un logiciel de simulation pour le faire. Mettez juste des flèches pour illustrer le cheminement du message envoyé, ensuite déterminez les routes (ou les adresses IP des interfaces) par lesquelles ce message passera pour arriver à son destinataire. Votre schéma doit ressembler au schéma Figure 1.2 (ici également, les adresses sont fictives et nous n’avons pas mis les masques de chaque adresse). Vous pouvez, bien entendu, résumer cela dans un tableau à défaut du schéma.
Ci-dessous les images d’illustration

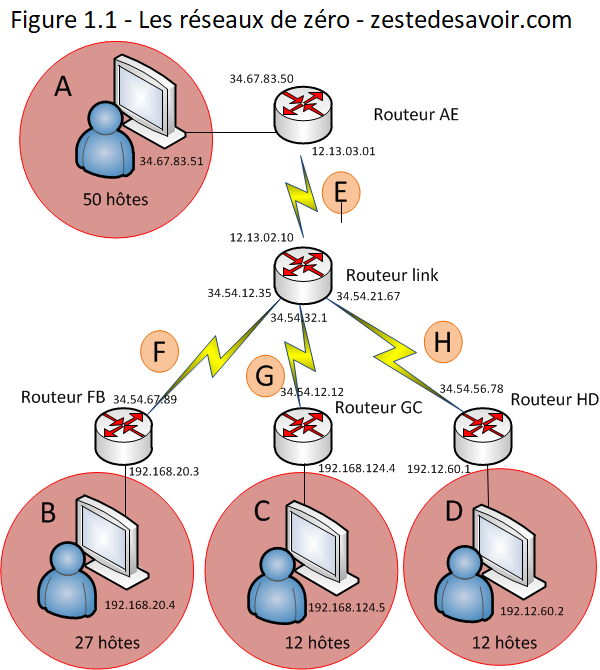

Voilà ! Lorsque vous aurez fini, vous pourrez poster vos solutions sur le forum.
Il est vraiment important de réussir ces exercices tout seul.
Nous espérons que vous avez compris tout l’intérêt de l’adressage CIDR. Nous escomptons que cela vous paraît évident maintenant que vous avez constaté par vous-même la différence entre l’adressage par classe et l’adressage CIDR.
Maintenant que vous avez bien tout appris concernant les adresses IPv4, passons à IPv6 !